Device Plugin
最近着手的项目中,涉及GPU的管理与调度,并且利用了Kubernetes进行部署,以及Kubernetes Scheduler进行调度。所以这一部分代码被定制化到Kubernetes的Repo中,随着Kubelet的启动而运行。
但是,痛点在于,Kubernetes的版本在不断更新,不同客户使用的k8s版本不同,导致代码在不断Merge、测试。重点是,在k8s 1.8版本中引入了Device Plugin概念,帮助客户驱动化管理GPU、FPGA等系统资源;并且在1.11版本中正式加入该功能,GPU相关的调度部署代码从被逐步移除。
Starting in version 1.8, Kubernetes provides a device plugin framework for vendors to advertise their resources to the kubelet without changing Kubernetes core code. Instead of writing custom Kubernetes code, vendors can implement a device plugin that can be deployed manually or as a DaemonSet. The targeted devices include GPUs, High-performance NICs, FPGAs, InfiniBand, and other similar computing resources that may require vendor specific initialization and setup.
Device Plugin API Design
在Device Plugin与k8s的体系中,Device Plugin实际上是一个gRPC server。Device Plugin需要通过/var/lib/kubelet/device-plugins/目录下的Unix Socket kubelet.sock向kubelet注册,提供gRPC服务;同时Device Plugin需要通过/var/lib/kubelet/device-plugins/目录下的Unix Socket,如nvidia.sock,监听来自kubelet的gRPC访问,提供相应服务(ListAndWatch,Allocate)。
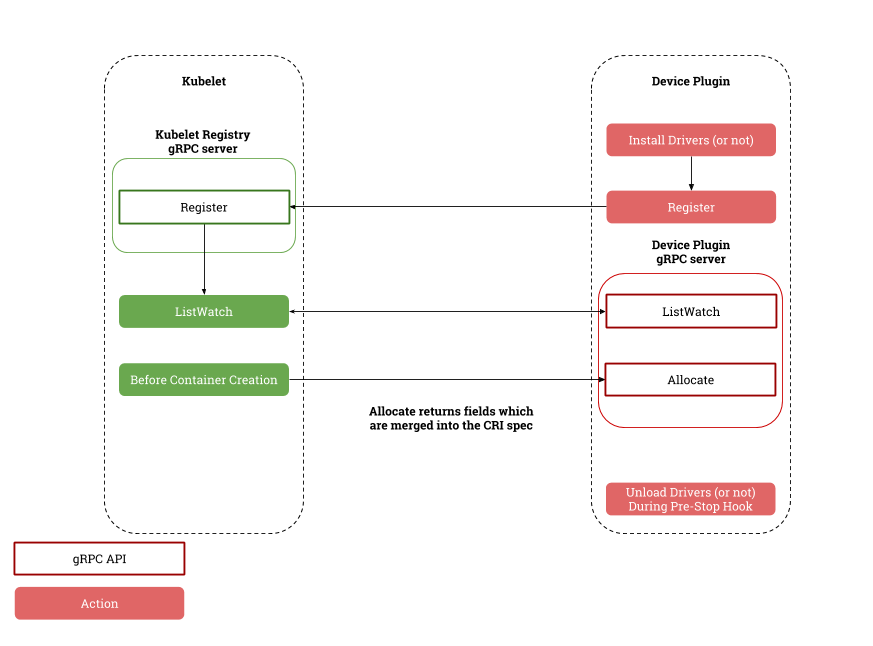
因此,创建Device Plugin可分三部分进行
- 注册
- 实现
- 部署
Device Plugin Registration
启动时,以gRPC的形式通过/var/lib/kubelet/device-plugins/kubelet.sock向Kubelet注册:
 注册时需提供Device Plugin的相应参数
注册时需提供Device Plugin的相应参数

- Version:Device Plugin API版本
- Endpoint:Unix socket,如/var/lib/kubelet/device-plugins/nvidia.sock
- ResourceName:Device Plugin所管理的资源,格式如vendor-domain/resource,如nvidia.com/gpu
Device Plugin Implementation
Device Plugin gRPC server主要提供两个方法

- ListAndWatch: 供Kubelet会调用,用于设备发现和健康状态更新
- Allocate: 当Kubelet创建要使用该设备的容器时, Kubelet会调用该API执行设备相应的操作并且通知Kubelet初始化容器所需的device,volume和环境变量的配置
备注:随意k8s版本的变更,Device Plugin所提供的接口服务也在逐步更新。
Device Plugin Deployment
通常以DaemonSet部署,需要将/var/lib/kubelet/device-plugins作为Volume Mount到Device Plugin的Pod中。
Case - NVIDIA Device Plugin
启动gRPC server,并向Kubelet发起注册请求
https://github.com/AlaricChan/k8s-device-plugin/blob/v1.11/vendor/k8s.io/kubernetes/pkg/kubelet/apis/deviceplugin/v1beta1/api.pb.go
https://github.com/AlaricChan/k8s-device-plugin/blob/v1.11/server.go
// Serve starts the gRPC server and register the device plugin to Kubelet
func (m *NvidiaDevicePlugin) Serve() error {
│ err := m.Start()
│ if err != nil {
│ │ log.Printf("Could not start device plugin: %s", err)
│ │ return err
│ }
│ log.Println("Starting to serve on", m.socket)
│ err = m.Register(pluginapi.KubeletSocket, resourceName)
│ if err != nil {
│ │ log.Printf("Could not register device plugin: %s", err)
│ │ m.Stop()
│ │ return err
│ }
│ log.Println("Registered device plugin with Kubelet")
│ return nil
}
向Kubelet发起注册请求
https://github.com/AlaricChan/k8s-device-plugin/blob/v1.11/server.go
// Register registers the device plugin for the given resourceName with Kubelet.
func (m *NvidiaDevicePlugin) Register(kubeletEndpoint, resourceName string) error {
│ conn, err := dial(kubeletEndpoint, 5*time.Second)
│ if err != nil {
│ │ return err
│ }
│ defer conn.Close()
│ client := pluginapi.NewRegistrationClient(conn)
│ reqt := &pluginapi.RegisterRequest{
│ │ Version: pluginapi.Version,
│ │ Endpoint: path.Base(m.socket),
│ │ ResourceName: resourceName,
│ }
│ _, err = client.Register(context.Background(), reqt)
│ if err != nil {
│ │ return err
│ }
│ return nil
}
NVIDIA Device Plugin向Kubelet提供对应的gRPC访问实现
https://github.com/AlaricChan/k8s-device-plugin/blob/v1.11/server.go
// ListAndWatch lists devices and update that list according to the health status
func (m *NvidiaDevicePlugin) ListAndWatch(e *pluginapi.Empty, s pluginapi.DevicePlugin_ListAndWatchServer) error {
│ s.Send(&pluginapi.ListAndWatchResponse{Devices: m.devs})
│ for {
│ │ select {
│ │ case <-m.stop:
│ │ │ return nil
│ │ case d := <-m.health:
│ │ │ // FIXME: there is no way to recover from the Unhealthy state.
│ │ │ d.Health = pluginapi.Unhealthy
│ │ │ s.Send(&pluginapi.ListAndWatchResponse{Devices: m.devs})
│ │ }
│ }
}
// Allocate which return list of devices.
func (m *NvidiaDevicePlugin) Allocate(ctx context.Context, reqs *pluginapi.AllocateRequest) (*pluginapi.AllocateResponse, error) {
│ devs := m.devs
│ responses := pluginapi.AllocateResponse{}
│ for _, req := range reqs.ContainerRequests {
│ │ response := pluginapi.ContainerAllocateResponse{
│ │ │ Envs: map[string]string{
│ │ │ │ "NVIDIA_VISIBLE_DEVICES": strings.Join(req.DevicesIDs, ","),
│ │ │ },
│ │ }
│ │ for _, id := range req.DevicesIDs {
│ │ │ if !deviceExists(devs, id) {
│ │ │ │ return nil, fmt.Errorf("invalid allocation request: unknown device: %s", id)
│ │ │ }
│ │ }
│ │ responses.ContainerResponses = append(responses.ContainerResponses, &response)
│ }
│ return &responses, nil
}
部署NVIDIA Device Plugin
https://github.com/AlaricChan/k8s-device-plugin/blob/v1.11/nvidia-device-plugin.yml
apiVersion: extensions/v1beta1
kind: DaemonSet
metadata:
name: nvidia-device-plugin-daemonset
namespace: kube-system
spec:
template:
metadata:
¦ # Mark this pod as a critical add-on; when enabled, the critical add-on scheduler
¦ # reserves resources for critical add-on pods so that they can be rescheduled after
¦ # a failure. This annotation works in tandem with the toleration below.
¦ annotations:
¦ scheduler.alpha.kubernetes.io/critical-pod: ""
¦ labels:
¦ name: nvidia-device-plugin-ds
spec:
¦ tolerations:
¦ # Allow this pod to be rescheduled while the node is in "critical add-ons only" mode.
¦ # This, along with the annotation above marks this pod as a critical add-on.
¦ - key: CriticalAddonsOnly
¦ operator: Exists
¦ containers:
¦ - image: nvidia/k8s-device-plugin:1.11
¦ name: nvidia-device-plugin-ctr
¦ securityContext:
¦ ¦ allowPrivilegeEscalation: false
¦ ¦ capabilities:
¦ ¦ drop: ["ALL"]
¦ volumeMounts:
¦ ¦ - name: device-plugin
¦ ¦ mountPath: /var/lib/kubelet/device-plugins
¦ volumes:
¦ - name: device-plugin
¦ ¦ hostPath:
¦ ¦ path: /var/lib/kubelet/device-plugins
References
https://kubernetes.io/docs/concepts/extend-kubernetes/compute-storage-net/device-plugins/
https://github.com/kubernetes/kubernetes/
https://yq.aliyun.com/articles/498185?utm_content=m_43607