Kubernetes Basics and Commands
初始化Master
$ sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address $YOUR_VM_IP
--apiserver-advertise-address指明用Master的哪个interface与Cluster的其他节点通信。如果Master有多个interface,建议明确指定,如果不指定,kubeadm会自动选择有默认网关的interface。
--pod-network-cidr指定Pod网络的范围。Kubernetes支持多种网络方案,而且不同网络方案对--pod-network-cidr有自己的要求,这里设置为10.244.0.0/16是因为我们将使用flannel网络方案,必须设置成这个CIDR。
初始化过程:
kubeadm执行初始化前的检查。
生成token和证书。
生成KubeConfig文件,kubelet需要这个文件与Master通信。
安装Master组件,会从goolge的Registry下载组件的Docker镜像,这一步可能会花一些时间,主要取决于网络质量。
安装附加组件kube-proxy和kube-dns。
Kubernetes Master初始化成功。
配置kubectl
$ mkdir -p $HOME/.kube
$ sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
$ sudo chown $(id -u):$(id -g) $HOME/.kube/config
为了使用更便捷,启用kubectl命令的自动补全功能。
echo "source <(kubectl completion bash)">> ~/.bashrc
查看Cluster详细信息
$ kubectl cluster-info
配置Pod网络
要让Kubernetes Cluster能够工作,必须安装Pod网络,否则Pod之间无法通信。
Kubernetes支持多种网络方案,这里我们先使用flannel
$ kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
添加Slaves
$ kubeadm join --token $TOKEN --discovery-token-ca-cert-hash sha256:$CA_HASH $MASTER_IP:6443
$ kubectl get pod --all-namespaces
$ kubectl describe pod <pod-name> -n kube-system
Kubernetes架构(Master)
Master
Master是Kubernetes Cluster的大脑,运行着如下Daemon服务:kube-apiserver、kube-scheduler、kube-controller-manager、etcd和Pod网络(例如flannel)。
API Server (kube-apiserver)
API Server提供HTTP/HTTPS RESTful API,即Kubernetes API。API Server是Kubernetes Cluster的前端接口,各种客户端工具(CLI或UI)以及Kubernetes其他组件可以通过它管理Cluster的各种资源。
Scheduler (kube-scheduler)
Scheduler负责决定将Pod放在哪个Node上运行。Scheduler在调度时会充分考虑Cluster的拓扑结构,当前各个节点的负载,以及应用对高可用、性能、数据亲和性的需求。
Controller Manager (kube-controller-manager)
Controller Manager负责管理Cluster各种资源,保证资源处于预期的状态。Controller Manager由多种controller组成,包括replication controller、endpoints controller、namespace controller、serviceaccounts controller等。
不同的controller管理不同的资源。例如replication controller管理Deployment、StatefulSet、DaemonSet的生命周期,namespace controller管理Namespace资源。
etcd
etcd负责保存Kubernetes Cluster的配置信息和各种资源的状态信息。当数据发生变化时,etcd会快速地通知Kubernetes相关组件。
Pod Networking
Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,flannel是其中一个可选方案。
Kubernetes架构(Node)
Node是Pod运行的地方,Kubernetes支持Docker、rkt等容器Runtime。Node上运行的Kubernetes组件有kubelet、kube-proxy和Pod网络。
Kubelet: kubelet是Node的agent,当Scheduler确定在某个Node上运行Pod后,会将Pod的具体配置信息(image、volume等)发送给该节点的kubelet,kubelet根据这些信息创建和运行容器,并向Master报告运行状态。
Kube-proxy: service在逻辑上代表了后端的多个Pod,外界通过service访问Pod。service接收到的请求是如何转发到Pod的呢?这就是kube-proxy要完成的工作。每个Node都会运行kube-proxy服务,它负责将访问service的TCP/UPD数据流转发到后端的容器。如果有多个副本,kube-proxy会实现负载均衡。
Pod Networking: Pod要能够相互通信,Kubernetes Cluster必须部署Pod网络,flannel是其中一个可选方案。
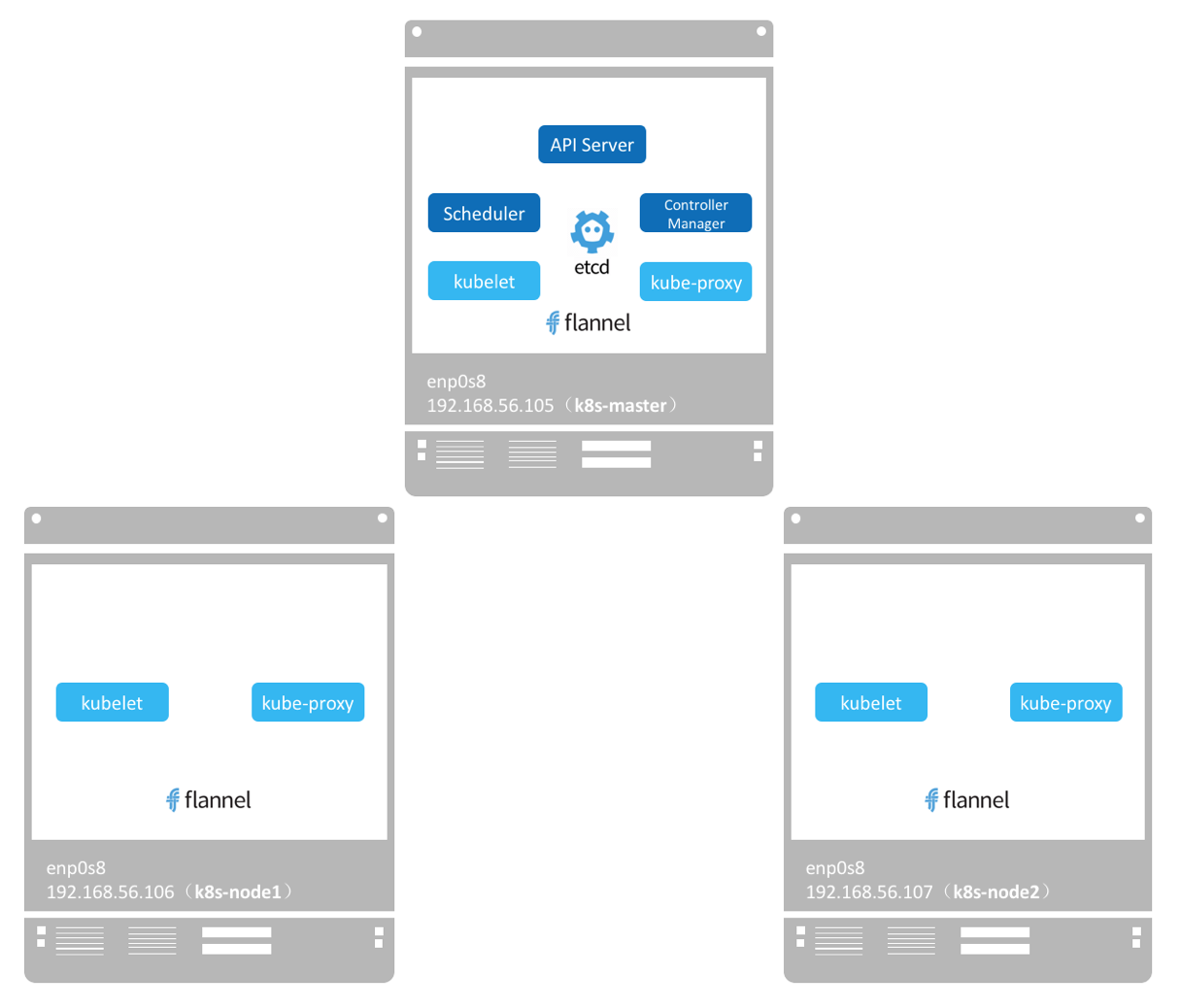
为什么k8s-master上也有kubelet和kube-proxy呢?
Master上也可以运行应用,即Master同时也是一个Node。
几乎所有的Kubernetes组件本身也运行在Pod里,执行如下命令:
$ kubectl get pod --all-namespaces
Kubernetes的系统组件都被放到kube-system namespace中。这里有一个kube-dns组件,它为Cluster提供DNS服务。kube-dns是在执行kubeadm init时作为附加组件安装的。
kubelet是唯一没有以容器形式运行的Kubernetes组件,它在Ubuntu中通过Systemd运行。
$ sudo systemctl status kubelet.service
部署应用
$ kubectl run httpd-app --image=httpd --replicas=2
$ kubectl get deployment
$ kubectl get pod -o wide
部署过程:
kubectl发送部署请求到API Server
API Server通知Controller Manager创建一个deployment资源
Scheduler执行调度任务,将两个副本Pod分发到Node
Node上的kubelet在各自的节点上创建并运行Pod

Deployment
前面我们已经了解到,Kubernetes通过各种Controller来管理Pod的生命周期。为了满足不同业务场景,Kubernetes开发了Deployment、ReplicaSet、DaemonSet、StatefuleSet、Job等多种Controller。以最常用的Deployment为例。
创建Deployment以及Pods
$ kubectl run nginx-deployment --image=nginx:1.7.9 --replicas=2
查看deployment的状态
$ kubectl get deployment <deployment-name>
查看Deployment的详细信息
$ kubectl describe deployment <deployment-name>
查看Replicaset详细信息
$ kubectl describe replicaset <replicaset-name>
查看Pod状态
$ kubectl get pod
查看Pod详细信息
$ kubectl describe pod <pod-name>
Deployment部署过程
a. 用户通过kubectl创建Deployment
b. Deployment创建ReplicaSet
c. ReplicaSet创建Pod

从上图也可以看出,对象的命名方式是:子对象的名字=父对象名字+随机字符串或数字。也验证了Deployment通过ReplicaSet来管理Pod的事实。
Kubernetes创建资源方式
Kubectl
$ kubectl run nginx-deployment --image=nginx:1.7.9 --replicas=2
Configuration (YAML)
$ kubectl apply -f nginx.yml
Deployment YAML
Deployment的配置格式,如:
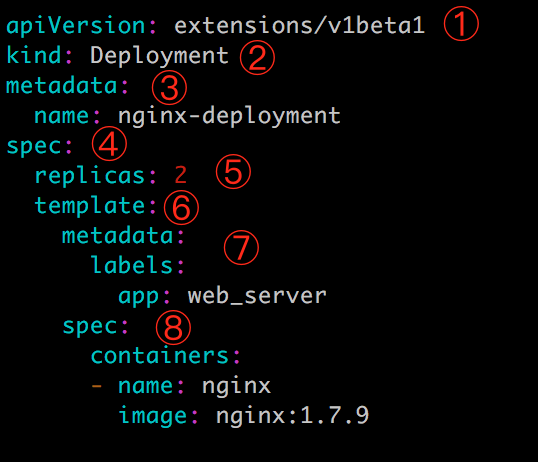
①apiVersion是当前配置格式的版本。
②kind是要创建的资源类型,这里是Deployment。
③metadata是该资源的元数据,name是必需的元数据项。
④spec部分是该Deployment的规格说明。
⑤replicas指明副本数量,默认为1。
⑥template定义Pod的模板,这是配置文件的重要部分。
⑦metadata定义Pod的元数据,至少要定义一个label。label的key和value可以任意指定。
⑧spec描述Pod的规格,此部分定义Pod中每一个容器的属性,name和image是必需的。
删除资源
$ kubectl delete deployment nginx-deployment
$ kubectl delete -f nginx.yml
Scale UP/Down
修改YAML的Replicas配置

出于安全考虑,默认配置下Kubernetes不会将Pod调度到Master节点。如果希望将k8s-master也当作Node使用,可以执行如下命令:
$ kubectl taint node k8s-master node-role.kubernetes.io/master-
如果要恢复Master Only状态,执行如下命令:
$ kubectl taint node k8s-master node-role.kubernetes.io/master="":NoSchedule
$ kubectl expose deployment/kubernetes-bootcamp --type="NodePort" --port 8080
Update Deployment
Update image of application to new version, use set image command
$ kubectl set image deployments/kubernetes-bootcamp kubernetes-bootcamp=jocatalin/kubernetes-bootcamp:v2
Verify an update
The update can be confirmed also by running a rollout status command
$ kubectl rollout status deployments/kubernetes-bootcamp
Rollback and update
Use the rollout undo command to roll back to our previously working version
$ kubectl rollout undo deployments/kubernetes-bootcamp
用label控制Pod的位置
默认配置下,Scheduler会将Pod调度到所有可用的Node。不过有些情况我们希望将Pod部署到指定的Node,比如将有大量磁盘I/O的Pod部署到配置了SSD的Node;或者Pod需要GPU,需要运行在配置了GPU的节点上。
Kubernetes是通过label来实现这个功能的。
label是key-value对,各种资源都可以设置label,灵活添加各种自定义属性。比如执行如下命令标注k8s-node1是配置了SSD的节点。
$ kubectl label node k8s-node1 disktype=ssd
$ kubectl get node --show-labels [-n kube-system]
有了disktype这个自定义label,接下来就可以指定将Pod部署到k8s-node1。编辑nginx.yml:

删除Pod上的Label
$ kubectl label node k8s-node1 disktype-
符号 - 即代表删除
不过此时Pod并不会重新部署,依然在k8s-node1上运行。
除非在nginx.yml中删除nodeSelector设置,然后通过kubectl apply重新部署。Kubernetes会删除之前的Pod并调度和运行新的Pod。
Service
在kubernetes中,Pod是变化的,虚拟IP也是变化的,比如通过ReplicaSets创建或者销毁Pod。
那么这样的Pod是如果为外部以及Kubernetes内部其他组件提供相关功能的?
Kubernetes引入了Service抽象概念,它定义了Pod的逻辑集合,以及访问它们的策略,也可以简单理解为一种微服务。通常情况下,Service与Pod是通过Label以及Label Selector来进行关联的。
通过YAML配置Service,如:
kind: Service //资源类型,这里为Service
apiVersion: v1
metadata: //资源元数据,Service name为my-service
name: my-service
spec: //规则说明
selector: //Pod Selector,Service访问Label为app=MyApp的Pods
app: MyApp
ports: //Service端口路由规则, 访问TCP协议9376的Pods,同时Service在Cluster内部通过80端口提供服务
- protocol: TCP
port: 80
targetPort: 9376
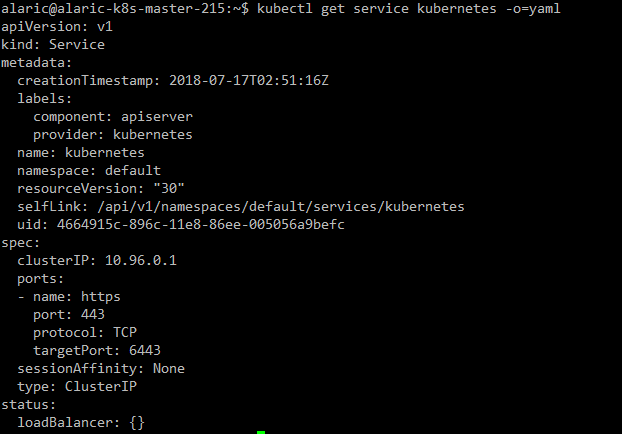
默认情况下(ClusterIP),Service会被分配一个虚拟IP,外部无法寻址,可以通过service proxies组件来实现的虚拟IP路由及转发。
通常类似web frontend是需要被Cluster以外的网络访问的,Kubernetes提供了不同的ServiceType,用户根据不同需求以及是否来对外发布Service,来选择不同的ServiceType,默认为ClousterIP。
ClusterIP: Service会被分配仅Cluster内部可访问的虚拟IP。
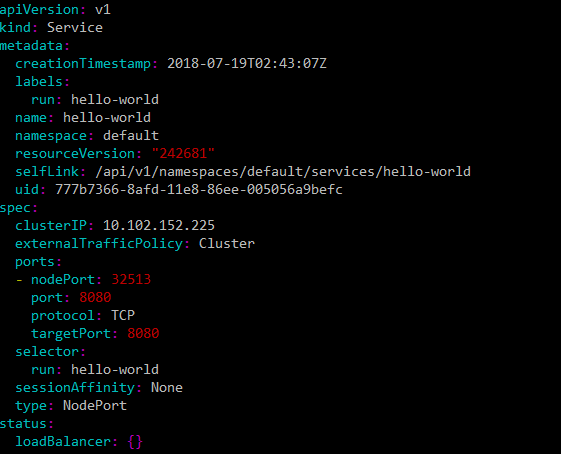
NodePort:在ClusterIP的基础上,在Cluster的每个Node上的暴露静态端口,在Cluster外部可以通过<NodeIP>:<NodePort>来进行访问
LoadBalancer:在NodePort的基础上,Kubernetes通过云平台提供的负载均衡器对外暴露服务。
ExternalName:创建CNAME映射Service,通过kube-dns解析相应Service。
Ingress,是一种HTTP方式的路由转发机制,由Ingress Controller和HTTP代理服务器组合而成。Ingress Controller实时监控Kubernetes API,实时更新HTTP代理服务器的转发规则。
以下为默认的ClusterIP类型的Service
以下为NodePort类型的Service
Volume
在容器化的设计中,容器中的数据是临时的,数据会随着容器的销毁而丢失。在Kubernetes Cluster中也是如此,当容器Crash或者被销毁时,容器中的数据丢失;而通常我们需要让Pod中的多个容器实现文件或者相同文件存储。Kubernetes引入Volume的抽象概念来解决上述问题。
目前Kubernetes支持的Volumes包括(不限):
awsElasticBlockStore
azureDisk
azureFile
cephfs
configMap
csi
downwardAPI
emptyDir
fc (fibre channel)
flocker
gcePersistentDisk
gitRepo (deprecated)
glusterfs
hostPath
iscsi
local
nfs
persistentVolumeClaim
projected
portworxVolume
quobyte
rbd
scaleIO
secret
storageos
vsphereVolume
PersistentVolume and PersistentVolumeClaim
用户通常并不需要关心和理解存储实现,只希望能够安全可靠地存储数据。Kubernetes中提供了Persistent Volume和Persistent Volume Claim两种API资源,实现存储消费模式。
Persistent Volume (PV)
PV是由Cluster管理员预创建的插件式存储,相对于Pod有着独立的生命周期。PV是Cluster中的一种资源,与Node相对于Cluster同理。
目前Kubernetes支持的PV插件包括(不限):
GCEPersistentDisk
AWSElasticBlockStore
AzureFile
AzureDisk
FC (Fibre Channel)
FlexVolume
Flocker
NFS
iSCSI
RBD (Ceph Block Device)
CephFS
Cinder (OpenStack block storage)
Glusterfs
VsphereVolume
Quobyte Volumes
HostPath (Single node testing only – local storage is not supported in any way and WILL NOT WORK in a multi-node cluster)
Portworx Volumes
ScaleIO Volumes
StorageOS
Persistent Volume Claim (PVC)
PVC是用户对Persistent Volume(存储)的请求。PV实现插件式的存储服务,PVC可以向PV请求存储的大小以及读写方式。PVC和PV的关系就像Node之于Pod,Pod消费Node资源,PVC消费PV。PVC与PV之间关系遵循以下生命周期管理:
Provisioning
由Cluster管理员创建,分静态和动态两种划分方式。
Binding
用户通过PVC来声明存储请求(存储大小以及读写方式)。PVC与PV的绑定是一对一的映射关系。
Using
对于使用者,PVC即是Volume。
Reclaiming
当用户结束使用PVC时,他们可以通过以下几种方式来回收释放Volume:
Retained: 允许手动回收Volume资源。当PVC被删除是,PV仍然保留,Volume处于released状态,由于前PVC的数据还在Volume中,此时PV不接收其他请求。管理员可以通过以下步骤释放Volume资源:
- 手动删除PV(PV被删除,但是存储数据仍然保留在外部存储中
- 删除存储中的数据
- 或者重新基于原存储定义,创建新的PV
Delete: PV以及存储数据一并清除。
Recycle: 如果相应的Volume支持Recycle回收机制,Recycle会进行基本的清理工作(rm -rf /thevolume/*),使得Volume可以被其他PVC请求获得。
